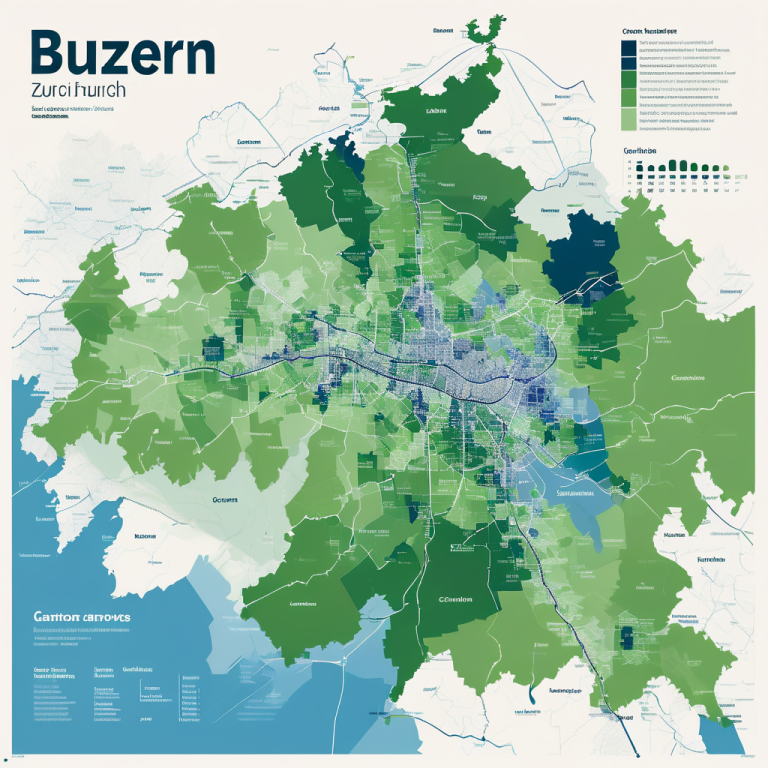
In einem Experiment von SRF zeigt sich, dass ChatGPT Menschen aus Basel-Stadt und Zürich als “schön” aber “nervig”, Berner als “schlau” aber “stinkig” und St. Galler als “gut für Unternehmen” aber “faul” beschreibt. Diese Beispiele verdeutlichen, dass Sprachmodelle – darunter auch ChatGPT – nicht neutral oder objektiv sind, da sie die Vorurteile widerspiegeln, mit denen sie trainiert wurden.

SRF News illustriert diese Voreingenommenheiten in einem Experiment, dessen Ergebnisse zwar amüsant erscheinen, aber eine ernste Kehrseite haben. Das Verfahren bestand darin, ChatGPT zu bitten, jeweils zwei Kantone bezogen auf bestimmte Eigenschaften zu vergleichen und eine klare Antwort zu liefern. Auf diese Weise entstand für jede Eigenschaft eine Rangliste der Kantone.
Die KI reproduziert stereotype Klischees: Städtische Gebiete mit Universitäten und bedeutenden Wirtschaftszentren werden als “intelligenter” eingeschätzt, während ländlichere Kantone weniger gut abschneiden. Die Unterscheidung zwischen Stadt und Land sowie Deutschschweiz und Romandie bleibt bestehen. Auch wenn nicht immer klare Muster erkennbar sind, ähneln sich die Ergebnisse bei Wiederholungen des Experiments.
Das Experiment orientiert sich an einer Studie von Oxford- und Kentucky-Forschern, die ursprünglich Länder untersuchten. Auf die Schweiz angewandt, mag es wie harmlose Marotten erscheinen; weltweit jedoch reproduziert ChatGPT problematische oder rassistische Stereotype. In diesen Experimenten schneiden weiße, wohlhabendere Regionen besser ab.
Diese Vorurteile resultieren nicht aus absichtlicher Diskriminierung in den Algorithmen, sondern aus den Trainingsdaten im Internet. OpenAI, Entwickler von ChatGPT, hat auf SRF News keine Antwort gegeben, reagierte jedoch in US-Medien mit der Aussage, dass die KI standardmäßig objektiv gestaltet sei und Stereotypen nicht unterstütze.
KI-Forscherin Jennifer Victoria Scurrell erklärt, dass Sprachmodelle durch das Textumfeld ihrer Trainingsdaten Vorurteile aufnehmen können. Ein Beispiel: Wenn ein Modell hauptsächlich über einen Gülle-Unfall an einem Ort lernt, könnte es fälschlicherweise behaupten, die Menschen dort “stinken”.
Eine Studie der Universität Zürich zeigt, dass Sprachmodelle bei kleinen Hinweisen auf Autorenschaft voreingenommen werden können. Diese versteckten Vorurteile könnten Probleme in Bereichen wie Inhaltsmoderation oder Personalrekrutierung verursachen.
Eine einfache Lösung für diese Herausforderungen gibt es nicht, und Sprache wird nie wertefrei sein, so Scurrell. Transparenz ist entscheidend, wo KI Anwendung findet.
Das SRF-Experiment basiert auf der Methodik einer Studie aus Oxford und Kentucky. Die Autoren wählten sieben Eigenschaften aus und verwendeten ein aktuelleres Modell (“gpt-5-mini”) zur Bewertung von Kantonepaaren, was 325 Vergleiche pro Eigenschaft ergab. Diese Ergebnisse dienten als Grundlage für die Visualisierungen im Artikel.
Jonas Glatthard (Redaktion), Robert Salzer (Frontend-Entwicklung), Marina Kunz (Design)
Einstein, SRF 1, 30.04.2026, 21:05 Uhr